分库分表
分库分表之扩容
分库、分表、垂直拆分和水平拆分
分库:因一个数据库支持的最高并发访问数是有限的,可以将一个数据库的数据拆分到多个库中,来增加最高访问数
分表:因一个表的数据量太大,用索引来查询数据都搞不定了,所以可以将一张表的数据拆分到多张表,查询时只需要查拆分后的某一张表,SQL 语句的查询性能得到提升
分库分表优势:分库分表后,承受的并发增加了多倍;磁盘使用率大大降低;单表数据量减少,sql 执行效率明显提升
水平拆分:把一个表的数据拆分到多个数据库,每个数据库中的表结构不变。用多个库抗更高的并发。比如订单表每个月有 500W 条数据累计,每个月都可以进行水平拆分,将上个月的数据放到另外一个数据库中
垂直拆分:把一个有很多字段的表,拆分成多张表到同一个库或者多个库上面。高频访问字段放到一张表,低频访问的字段放到另外一张表。利用数据库缓存来缓存高频访问的行数据。比如一张很多字段的订单表拆分成几张表分别存不同的字段(可以有冗余字段)
分库分表的方式
利用租户来分库、分表
利用字段范围来分库、分表
利用字段 hash 来分库、分表
垂直拆分带来的问题
- 依然存在单表数据量过大的问题
- 部分表无法关联查询,只能通过接口聚合的方式解决,提升了开发的复杂度
- 分布式事务处理复杂
水平拆分带来的问题
- 跨库的关联查询性能差
- 数据多次扩容和维护量大
- 跨分片的事务一致性难以保证
分库分表之唯一 ID
为什么分库分表需要唯一 ID
如果要做分库分表,则必须考虑主键 ID 是全局唯一的,比如有一张订单表,被分到 A 库和 B 库,如果两张表都是从 1 开始递增,那么查询数据的时候就乱了,很多订单 ID 都是重复的,而这些订单其实并不是一笔订单
分库的一个期望结果就是将访问数据的次数分摊到其他库,有些场景是需要均匀分摊的,那么数据插入到多个数据库的时候就需要交替生成唯一的 ID 来保证请求均匀分摊到所有数据库
生成唯一 ID 的原则
全局唯一
趋势递增
单调递增
信息安全
生成唯一 ID 的几种方式
数据库自增 ID,每个数据库每增加一条记录,自己的 ID 增 1
- 多个库的 ID 可能重复,不适合分库分表后的 ID 生成
- 信息不安全
UUID
- UUID 太长,占用空间大
- 不具有有序性,作为主键时,在写入数据时,不能产生有顺序的 append 操作,只能进行 insert 操作,导致读取整个 B+树节点到内存,插入数据后将整个节点写回磁盘,当记录占用空间很大时,性能很差
获取系统当前时间作为唯一 ID
- 高并发时,1ms 内可能有多个相同的 ID
- 信息不安全
Twitter 的snowflake(雪花算法):twitter 开源的分布式 id 生成算法,64 位的 long 型的 id,分为 4 部分
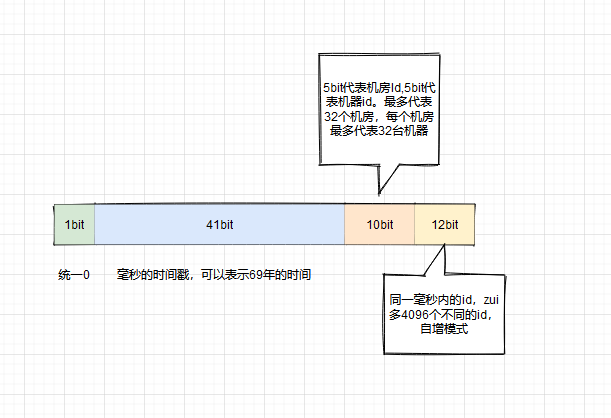
- 优点:
- 毫秒数在高位,自增序列在低位,整个 ID 都是趋势递增的
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成 ID 的性能也是非常高的
- 可以根据自身业务特性分配 bit 位,非常灵活
- 缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态
百度的UIDGenerator算法
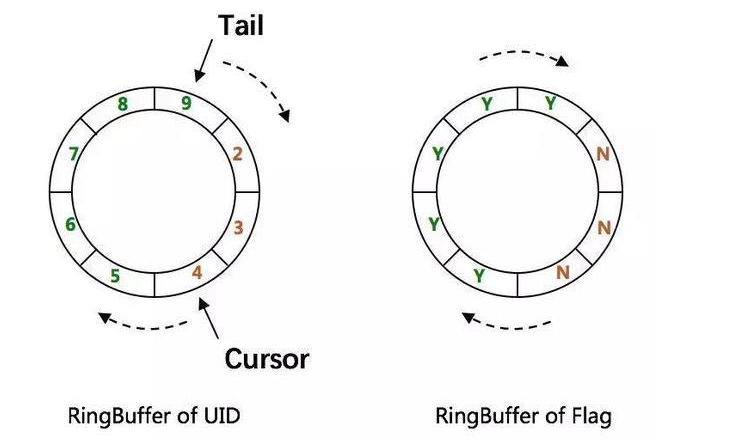
- 基于 snowflake 的优化算法
- 借用未来时间和双 buffer 来解决时间回拨与生成性能等问题,同时结和 mysql 进行 ID 分配
- 优点:解决了时间回拨和生成性能问题
- 缺点:依赖 mysql 数据库
美团的Leaf-snowflake算法
- 获取 id 是通过代理服务访问数据库获取一批 id(号段)
- 双缓冲:当前一批的 id 使用 10%时,再访问数据库获取新的一批 id 缓存起来,等上批的 id 用完之后直接用
- 优点:
- leaf 服务可以很方便的线性拓展,性能完全能够支撑大多数业务场景
- id 号码时趋势递增的 8byte 的 64 位数字,满足上述数据库存储的主键要求
- 容灾性高:leaf 服务内部有号段缓存,即使 DB 宕机,短时间内 leaf 仍能正常对外提供服务
- 可以自定义 max_id 的大小,非常方便业务从原有的 id 方式上迁移过来
- 即使 DB 宕机,leaf 仍能持续发号一段时间
- 偶尔的网络抖动不会影响下个号段的更新
- 缺点:
- ID 号码不够随机,能够泄漏发号数量的信息,不太安全
分布式事务
在分布式的世界中,存在着各个服务之间相互调用,链路可能很长,如果有任何一方执行出错,则需要回滚涉及到的其他服务的相关操作。比如订单服务下单成功,然后调用营销中心发券接口发了一张代金券,但是微信支付扣款失败,则需要退回发的那张券,且要将订单状态改为异常订单
分布式事务的几种主要方式
- XA 方案(两段式提交)
- TCC 方案(try、confirm、cancel)
- SAGA 方案
- 可靠消息最终一致性方案
- 最大努力通知方案
XA 方案原理
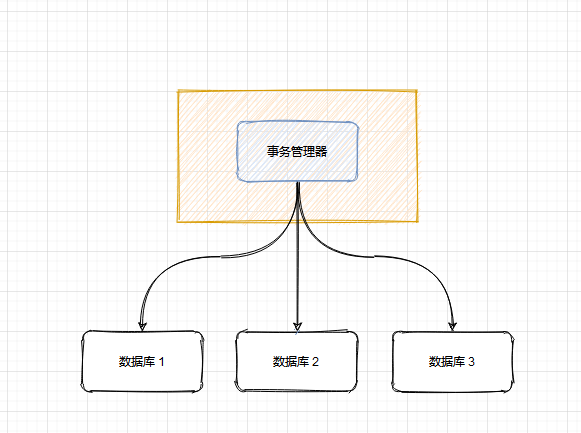
- 事务管理器负责协调多个数据库的事务,先问问各个数据库准备好了吗?如果准备好了,则在数据库执行操作,如果任何一个数据库没有准备好,则不执行事务
- 适合单体应用,不适合微服务架构,因为每个服务只能访问自己的数据库,不允许交叉访问其他微服务的数据库
TCC 方案
try 阶段:对各个服务的资源做检测以及对资源进行锁定或者预留
confirm 阶段:各个服务中执行实际的操作
cancel 阶段:如果任何一个服务的业务方法执行出错,需要将之前操作成功的步骤进行回滚
应用场景:
- 跟支付、交易打交道,必须保证资金正确的场景
- 对于一致性要求很高
缺点:
- 要写很多补偿逻辑的代码,且不易维护
Saga 方案
- 基本原理:
- 业务流程中的每个步骤若有一个失败了,则补偿前面操作成功的步骤
- 适用场景:
- 业务流程长、业务流程多
- 参与者包含其他公司或遗留系统服务
- 优势:
- 第一个阶段提交本地事务,无锁,高性能
- 参与者可异步执行,高吞吐
- 补偿服务易于实现
- 缺点:
- 不保证事务的隔离性
可靠消息一致性方案
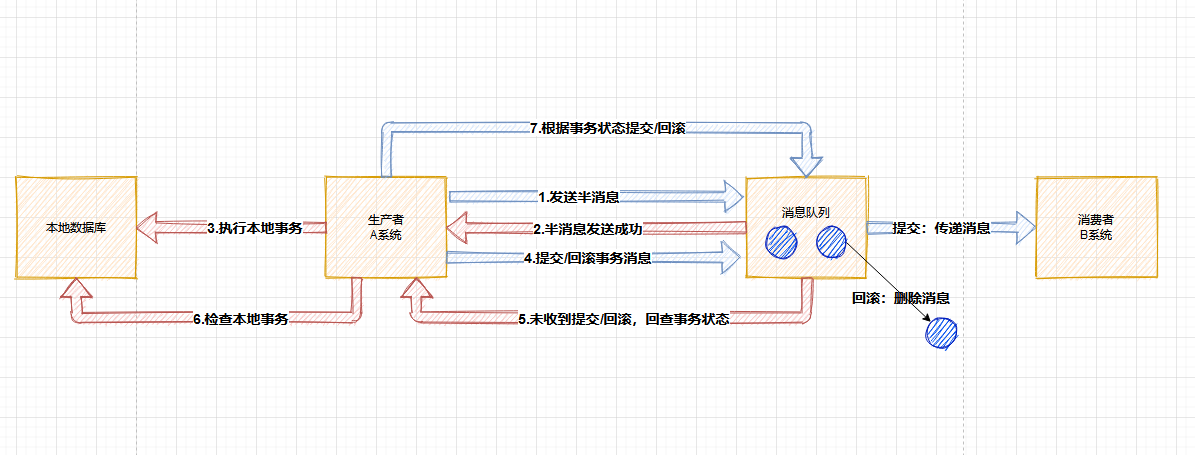
基本原理:
- 利用消息中间件RocketMQ来实现消息事务
- 第一步:A 系统发送一个prepared(预备状态,半消息)消息到 MQ,该消息无法被订阅
- 第二步:MQ 响应 A 系统,告诉 A 系统已经接收到消息了
- 第三步:A 系统执行本地事务
- 第四步:若 A 系统执行本地事务成功,将prepared消息改为commit(提交事务消息),B 系统就可以订阅到消息了
- 第五步:MQ 也会定时轮询所有prepared消息,回调 A 系统,让 A 系统告诉 MQ 本地事务处理的怎么样了,是继续等待还是回滚
- 第六步:A 系统收到MQ回查,检查本地事务的执行结果
- 第七步:若 A 系统执行本地事务失败,则 MQ 收到Rollback信号,丢弃消息。若执行本地事务成功,则 MQ 收到commit信号
- B 系统收到消息后,开始执行本地事务,如果执行失败,则自动不断重试直到成功。或 B 系统采取回滚的方式,同时要通过其他方式通知 A 系统也进行回滚
- B 系统需要保证幂等性
最大努力通知方案
基本原理:
- 系统 A 本地事务执行完成之后,发送消息到 MQ
- MQ 将消息持久化
- 系统 B 如果执行本地事务失败,则最大努力服务会定时尝试重新调用系统 B,尽自己最大的努力让系统 B 重试,重试多次后,还是不行就只能放弃了。通知开发人员去排查以及后续人工补偿
几种方案如何选择
- 跟支付、交易打交道,优先 TCC
- 大型系统,但要求不那么严格,考虑消息事务或 SAGA 方案
- 单体应用,建议 XA 两阶段提交就可以
- 最大努力通知方案建议都加上,毕竟不可能一出问题就交给开发排查,先重试几次看看能不能成功