new Object()占多少个字节
mark word(8 字节)+klass(4 字节,默认开启指针压缩)+padding(4 字节) = 16 字节
mark word(8 字节)+klass(8 字节,不开启指针压缩) = 16 字节
User (int id,String name) User u = new User(1,”李四”)
mark word(8 字节)+klass(4 字节,默认开启指针压缩)+instance data int(4 字节) + 开启普通对象指针压缩后 String(4 字节)+padding(4 字节) = 24 字节
线程交替打印
实现两个线程交替打印,实现字母在前数字在后,可以用信号量,synchronized 关键字和 Lock 实现
1 | import java.util.concurrent.CountDownLatch; |
线程之间如何通信
共享内存: 隐式通信
消息传递: 显示通信
线程之间如何同步
在共享内存的并发模型中,同步是显示做的; synchronized
在消息传递的并发模型中,由于消息发布必须在消息接收之前,所以同步是隐式
volatile 和 Synchronized 区别
volatile 可见性/原子性,不能做到复合操作的原子性
1.对于声明了 volatile 的变量进行写操作的时候,JVM 会向处理器发送一条 Lock 前缀的指令,会把这个变量所在缓存行的数据写回到主内存
2.在多处理器的情况下,保证各个处理器缓存一致性的特点,就会实现缓存一致性协议
synchronized 可重入锁/互斥性/可见性/有序性
如何保证多线程顺序执行
- 通过 join: 让主线程等待子线程执行结束之后才能继续进行
- 单线程的线程池: Executors.newSingleThreadExecuotr();
Lock 和 Synchronized 区别
Lock: java5 以后出现的 JUC 包中的(java.util.concurrent.locks)
1.Synchronized 锁什么时候释放
获取锁的线程执行完了该代码块
线程执行出现异常
线程和进程的概念
每个应用程序是一个进程,一个进程里可以运行多个线程,多个线程是为了更好的利用 CPU 资源
两个 Integer 的引用对象传给一个 swap 方法在方法内部进行交换,返回后,两个引用的值是否会发生变化
1 | private static void swap(Integer a, Integer b) throws NoSuchFieldException, IllegalAccessException { |
阻塞 IO 和非阻塞 IO
七层网络模型
应用层
表示层
会话层
传输层
网络层
数据链路层
物理层
mysql 的 binlog
记录 mysql 的数据更新和潜在更新
主从复制依赖 binlog
master 写数据之后写到 binlog,发送事件通知
slave IO 线程读取 binlog,写入 relay log
slave sql 线程从 relay log 读取语句执行
三种格式:
statement: 基于 sql 语句
row: 基于行模式,记录变更的数据
mixed: 混合模式,
cookie 和 session 的关联关系
cookie 在客户端保存信息,session 在服务端保存信息
服务端生成 JSESSIONID,当作 key 存入 ConcurrentHashMap,value 存储客户端信息,将 JSESSIONID 返回给客户端
客户端将 JSESSIONID 存入 cookie
把用户信息存储到 session 中,关闭浏览器,session 就失效了
分布式架构 session 共享和 session 复制
1.session 复制:每个节点都复制 session
2.客户端保存唯一 id,服务端把 session 存入 redis
3.jwt
AOP 底层实现原理
动态代理
字节码
为什么不能直接调用 run()方法启动线程
JVM 执行 start()方法,会另外启动一个线程去执行 thread 的 run()方法,这时执行 start()的方法和执行 run()方法的线程会并行,
重复执行 start()方法,会抛出 IllegalThreadStateException
如何保证多线程下 i++结果正确
使用 CAS+原子类
使用锁机制
使用 synchronized
谈谈你理解的 HashMap,讲讲其中的 get put 过程
1.8 做了什么优化?
是线程安全的嘛?
不安全会导致哪些问题?
如何解决?有没有线程安全的并发容器?
ConcurrentHashMap 是如何实现的?1.7、1.8 实现有何不同,为什么这么做
1.8 中 ConcurrentHashMap 的 sizeCtl 作用,大致说下协助扩容跟标志位
HashMap 为什么不用跳表替换红黑树呢?
synchronized 跟 ReentrantLock 使用区别跟底层实现以及重入底层原理
描述下锁的四种状态跟升级过程
CAS 是什么?CAS 的弊端是什么?
你对 volatile 的理解,可见性跟指令重排咋实现的
一个对象创建过程是怎么样的对象在内存中如何分布的,看 JVM 即可
聊一聊单例模式,为什么 DCL 要用 volatile
你对 as-if-serial 跟 happpends-before 的理解
ThreadLocal 说一说,咋解决内存泄露
自旋锁一定比重量级锁效率高吗?偏向锁是否效率一定提高
线程池聊一聊如何用 注意细节,如何实现
你对 JMM 理解?
Synchronized 可以实现指令重排么?它是如何保证有序性的?
聊一聊 AQS,为什么 AQS 底层是 CAS + Volatile
为什么不建议用 uuid 做 MySQL 的主键
1.适用自增 id 的内部结构
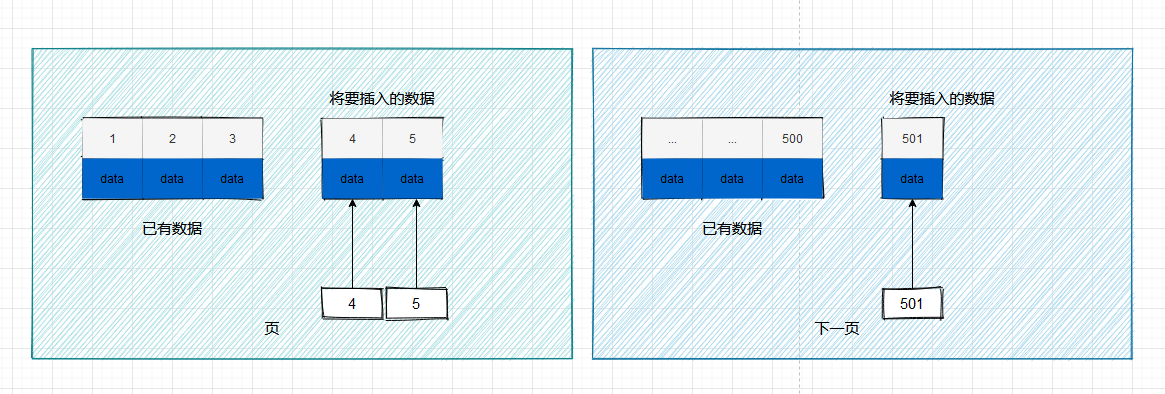
自增主键的值是顺序的,所以 innoDB 把每一条记录都存储在之前记录的后面。当达到页面的最大填充因子的时候(innoDB 默认的最大填充因子是页大小的 15/16,会留出 1/16 的空间留作以后的修改)
这样做的好处是:
下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
新插入的行一定会在原有的最大行的下一行,mysql 定位和寻址很快,不会为计算新行的位置而做出额外的消耗
减少了页分裂和碎片的产生
2.使用 uuid 的索引内部结构
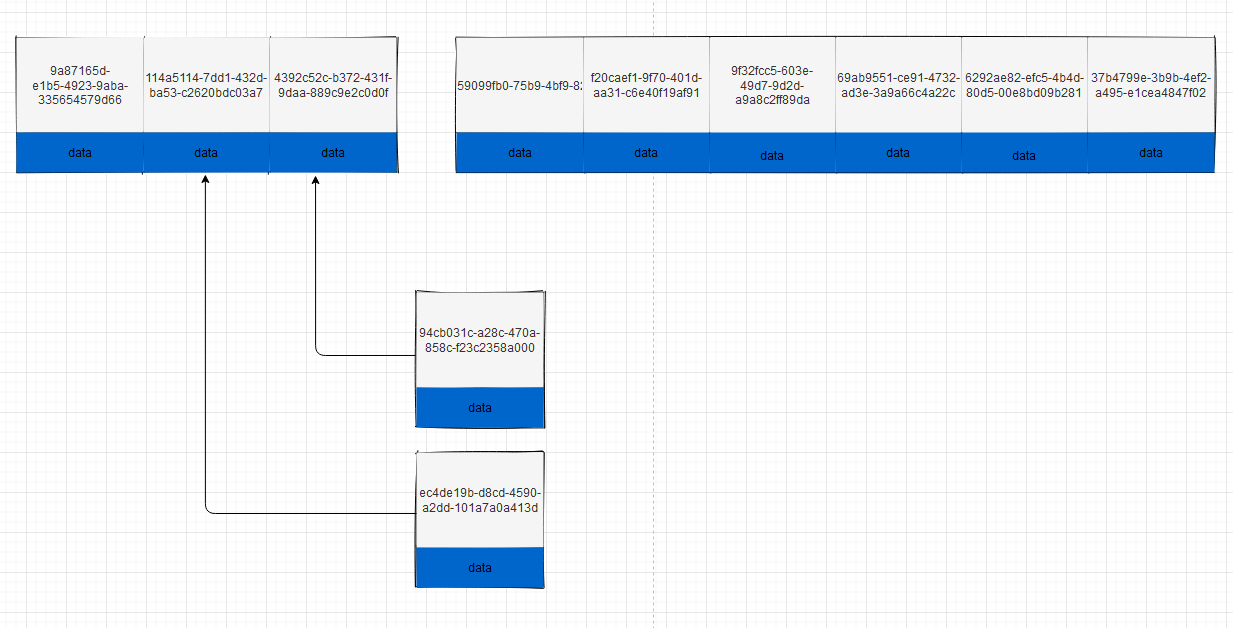
插入 UUID:新的记录可能会插入之前记录的中间,新的行需要强制移动之前的记录
被写满已经刷新到磁盘上的页可能会被重新读取
因为 UUID 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值大,所以 innoDB 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱。将会导致以下的问题:
写入的目标页很可能已经刷新到磁盘上并且从缓存中移除,或者还没有被加载到缓存中,innoDB 在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机 IO
因为写入时乱序的,innoDB 不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改 3 个页以上
由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据有碎片
在把随机值载入到聚簇索引以后,有时候会需要做一次 OPTIMEIZE TABLE 来重建表并优化页的填充,这将又需要一定的时间消耗
结论:使用 innodb 应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行
3.使用自增 id 的缺点
自增 id 也会存在以下几点问题:
1.别人一旦爬取你的数据库,就可以根据数据库的自增 id 获取到你的业务增长信息,很容易分析出你的经营情况
2.对于高并发的负载,innodb 在按主键进行插入的时候会造成明显的锁竞争,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
3.Auto_Increment 锁机制会造成自增锁的抢夺,有一定的性能损失