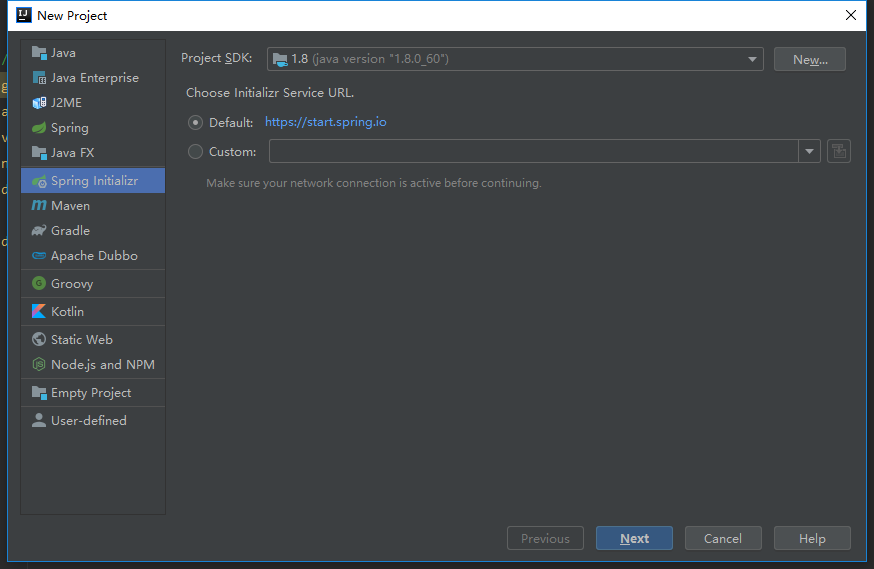
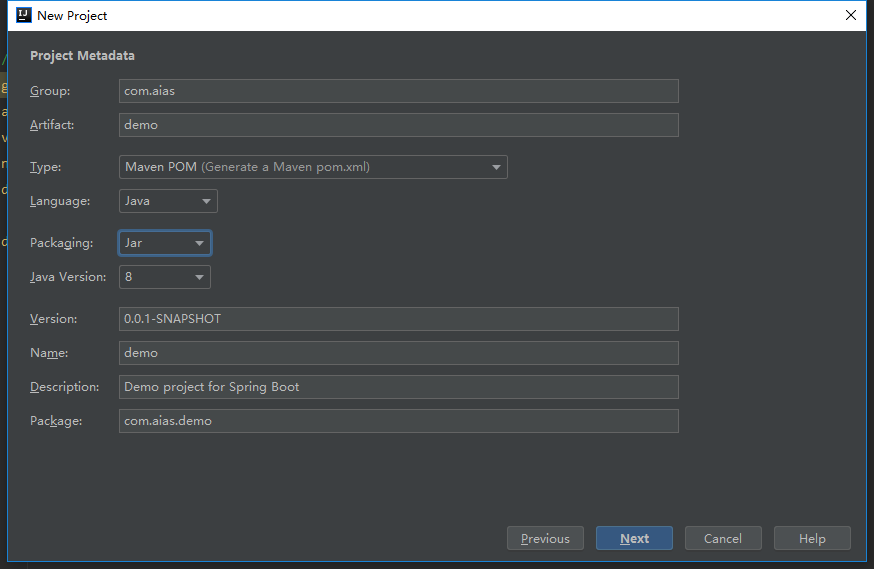
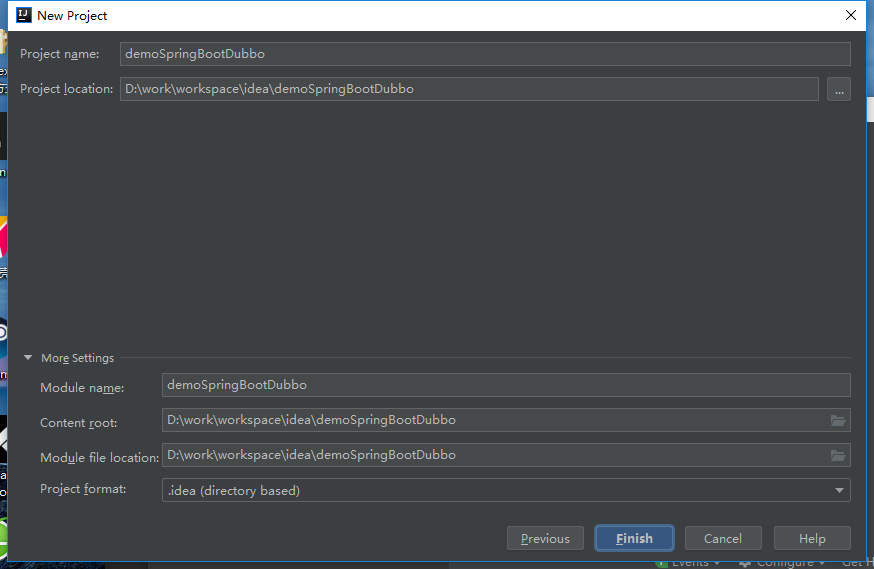
在应用 spring 框架进行开发时,我们常常用@Resource 和@Autowired 注解进行依赖注入
在开发过程中仿佛这两者应用起来并没有什么区别,但是其实这两个注解本质上就是不一样的
区别如下:
@Resource 是由 java 提供的注解,而@Autowired 是由 spring 提供的
@Resource 是 ByName,而@Autowired 是 ByType
@Autowire 注入时 ByType 如果要使用 ByName 需要配合@Qualifier
1 |
|
在应用 spring 框架进行开发时,我们常常用@Resource 和@Autowired 注解进行依赖注入
在开发过程中仿佛这两者应用起来并没有什么区别,但是其实这两个注解本质上就是不一样的
区别如下:
@Resource 是由 java 提供的注解,而@Autowired 是由 spring 提供的
@Resource 是 ByName,而@Autowired 是 ByType
@Autowire 注入时 ByType 如果要使用 ByName 需要配合@Qualifier
1 |
|
公司的一个服务用了一个单台 redis 服务器,本来配置 redis 的 maxmemory 只有 512M,但是服务跑了几个月都没什么问题,说明是够用的。
但是最近不到一个月的时间的时间,这台服务器的 redis 报了两次内存不足,最开始是以为调用量慢慢上来了,所以只是单纯的修改 maxmemory 的值,修改到了 3g。
昨天观察了一下发现内存占用已经到了 2.3g 了,这马上又快满了,觉得不对劲,所以想要分析一下是哪些 key 占用的空间比较大,看看能不能相应的优化一下代码
CentOS Linux release 7.2.1511
redis-5.0.4
python2.7
git